自1.8.3版本发布以来,Doxygen提供了使用外部索引工具和搜索引擎搜索HTML的能力。这有几个优点:
为了避免每个人都必须开始编写自己的索引器和搜索引擎,Doxygen为每个操作提供了一个示例工具:doxyindexer 用于索引数据,doxysearch.cgi 用于搜索索引。
数据流如下图所示:
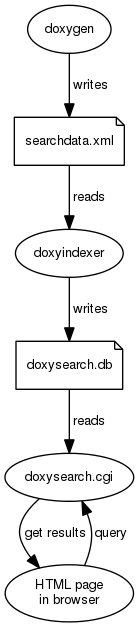
第一步是通过Web服务器使搜索引擎可用。如果您使用 doxysearch.cgi,这意味着使 CGI 二进制文件可从Web服务器获得(即能够通过以http:开头的URL从浏览器运行它)
如何设置Web服务器超出了本文档的范围,但是如果您安装了Apache,您可以简单地将Doxygen的 bin 目录中的 doxysearch.cgi 文件复制到Apache Web服务器的 cgi-bin 目录。有关详细信息,请阅读 apache文档。
要测试 doxysearch.cgi 是否可访问,请启动您的Web浏览器并指向二进制文件的URL,并在末尾添加 ?test
http://yoursite.com/path/to/cgi/doxysearch.cgi?test
您应该会收到以下消息:
Test failed: cannot find search index doxysearch.db
如果您使用Internet Explorer,可能会提示您下载一个文件,该文件将包含此消息。
由于我们没有创建或安装 doxysearch.db,因此测试因此原因失败是正常的。如何在下一节中讨论如何纠正此问题。
在继续下一节之前,将上述URL(不带 ?test 部分)添加到Doxygen配置文件中的 SEARCHENGINE_URL 标签中。
SEARCHENGINE_URL = http://yoursite.com/path/to/cgi/doxysearch.cgi
要使用外部搜索选项,请确保Doxygen配置文件中启用了以下选项:
SEARCHENGINE = YES SERVER_BASED_SEARCH = YES EXTERNAL_SEARCH = YES
这将使Doxygen在输出目录(通过 OUTPUT_DIRECTORY 配置)中生成一个名为 searchdata.xml 的文件。您可以使用 SEARCHDATA_FILE 选项更改文件名(和位置)。
下一步是将原始搜索数据放入索引中以进行高效搜索。您可以使用 doxyindexer。只需从命令行运行它:
doxyindexer searchdata.xml
这将创建一个名为 doxysearch.db 的目录,其中包含一些文件。默认情况下,该目录将创建在 doxyindexer 启动的位置,但您可以使用 -o 选项更改目录。
将 doxysearch.db 目录复制到 doxysearch.cgi 所在的同一目录,并通过将浏览器指向以下URL来重新运行浏览器测试:
http://yoursite.com/path/to/cgi/doxysearch.cgi?test
您现在应该会收到以下消息:
Test successful.
现在您应该能够从HTML输出中搜索单词和符号。
如果您有多个Doxygen项目并且这些项目相关,则可能希望在任何项目的文档中搜索所有项目中的单词。
要实现这一点,只需将所有项目的搜索数据组合到一个索引中,例如,对于项目A和项目B,其searchdata.xml文件分别在project_A和project_B目录中生成,运行:
doxyindexer project_A/searchdata.xml project_B/searchdata.xml
然后将生成的 doxysearch.db 复制到 doxysearch.cgi 所在的目录。
searchdata.xml 文件不包含任何绝对路径或链接,那么如何将来自多个项目的搜索结果链接回正确的文档集呢?这就是 EXTERNAL_SEARCH_ID 和 EXTRA_SEARCH_MAPPINGS 选项发挥作用的地方。
为了能够识别不同的项目,需要为每个项目使用 EXTERNAL_SEARCH_ID 设置一个唯一的ID。
要将搜索结果链接到正确的项目,您需要使用 EXTRA_SEARCH_MAPPINGS 标签为每个项目定义一个映射。通过此选项,您可以定义从其他项目的ID到这些项目的文档的(相对)位置的映射。
因此,对于项目A和项目B,配置文件的相关部分可能如下所示:
project_A/Doxyfile ------------------ EXTERNAL_SEARCH_ID = A EXTRA_SEARCH_MAPPINGS = B=../../project_B/html
对于项目A和项目B:
project_B/Doxyfile ------------------ EXTERNAL_SEARCH_ID = B EXTRA_SEARCH_MAPPINGS = A=../../project_A/html
通过这些设置,项目A和项目B可以共享相同的搜索数据库,并且搜索结果将链接到正确的文档集。
当您修改源代码时,您应该重新运行 doxygen 以再次获取最新文档。当使用外部搜索时,您还需要通过重新运行 doxyindexer 来更新搜索索引。您可以将对 doxygen 和 doxyindexer 的调用封装在脚本中,以使此过程更容易。
前面的部分假设您使用工具 doxyindexer 和 doxysearch.cgi 来执行索引和搜索,但您也可以根据需要编写自己的索引和搜索工具。
为此,3个接口很重要:
接下来的小节将更详细地描述这些接口。
Doxygen生成的搜索数据遵循 Solr XML索引消息 格式。
索引器的输入是一个XML文件,它由一个 <add> 标签组成,该标签包含多个 <doc> 标签,而 <doc> 标签又包含多个 <field> 标签。
这是一个doc节点的示例,其中包含一个方法的搜索数据和元数据:
<add>
...
<doc>
<field name="type">function</field>
<field name="name">QXmlReader::setDTDHandler</field>
<field name="args">(QXmlDTDHandler *handler)=0</field>
<field name="tag">qtools.tag</field>
<field name="url">de/df6/class_q_xml_reader.html#a0b24b1fe26a4c32a8032d68ee14d5dba</field>
<field name="keywords">setDTDHandler QXmlReader::setDTDHandler QXmlReader</field>
<field name="text">Sets the DTD handler to handler DTDHandler()</field>
</doc>
...
</add>
每个字段都有一个名称。支持以下字段名称:
当从Doxygen生成的HTML页面调用搜索引擎时,通过 查询字符串 传递多个参数。
传递以下字段:
从完整的搜索结果列表中,应返回范围 [n*p - n*(p+1)-1]。
这是一个查询示例:
http://yoursite.com/path/to/cgi/doxysearch.cgi?q=list&n=20&p=1&cb=dummy
它表示对单词“list”(q=list)的查询,请求20个搜索结果(n=20),从结果编号20开始(p=1),并使用回调“dummy”(cb=dummy)。
如上一小节所示调用搜索引擎时,它应该回复结果。回复的格式是 带填充的JSON,它基本上是一个包装在函数调用中的JavaScript结构。函数的名称应该是回调的名称(如查询中通过 cb 字段传递的)。
使用上一小节所示的示例查询,回复的主要结构应如下所示:
dummy({
"hits":179,
"first":20,
"count":20,
"page":1,
"pages":9,
"query": "list",
"items":[
...
]})
这些字段具有以下含义:
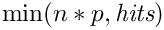 。
。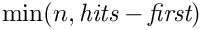
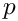
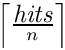 。
。以下是 items 数组元素应如何的示例:
{"type": "function",
"name": "QDir::entryInfoList(const QString &nameFilter, int filterSpec=DefaultFilter, int sortSpec=DefaultSort) const",
"tag": "qtools.tag",
"url": "d5/d8d/class_q_dir.html#a9439ea6b331957f38dbad981c4d050ef",
"fragments":[
"Returns a <span class=\"hl\">list</span> of QFileInfo objects for all files and directories...",
"... pointer to a QFileInfoList The <span class=\"hl\">list</span> is owned by the QDir object...",
"... to keep the entries of the <span class=\"hl\">list</span> after a subsequent call to this..."
]
},
此类项目的字段具有以下含义:
